A Fondo
Machine Learning: cuando aprenden las máquinas

Vivimos en un mundo en el que Netflix nos recomienda la próxima serie que «nos va a encantar», Amazon es capaz de detectar y anticiparse a nuestra próxima compra y Google Fotos reconoce prácticamente cualquier objeto en las imágenes que almacenamos. Las máquinas aprenden ¡vaya si lo hacen! y en los últimos tiempos, a toda velocidad.
Los nuevos servicios financieros comprenden casi automáticamente si deberíamos cambiar de compañía eléctrica o pedir un crédito y las redes sociales prometen mostrarnos sólo los contenidos que nos interesan. Termostatos inteligentes como Nest estudian nuestros hábitos para crear un clima confortable en nuestro hogar y asistentes virtuales como Alexa o Google Assistant nos conocen un poquito más cada día que pasa.
¿Pero cómo lo hacen? ¿Cómo estamos enseñando a las máquinas a aprender habilidades nuevas? ¿De qué forma construimos ese conocimiento nuevo que después emplea la Inteligencia Artificial? En MCPRO os hablamos de cómo fuciona el machine learning. Os mostramos qué técnicas estamos empleando para que las máquinas «aprendan a aprender», cuáles son los programas que lo hacen posible y hasta qué punto sigue siendo necesaria la intervención humana.
Aprendiendo a aprender
Para entender cómo estamos enseñando a las máquinas a aprender habilidades nuevas, podemos pensar en cómo enseñamos a los niños a aprender el alfabeto. Cómo en primer lugar el profesor les muestra los distintos trazos (rectos y curvos) y cómo a partir de los mismos se forman las letras, desde las más sencillas a las más complejas. Así en un proceso de aprendizaje basado sobre todo en la repetición el profesor obliga a los niños que llenen hojas y cuadernos completos: primero con trazos rectos, después con formas redondas, a continuación las primeras letras y finalmente el alfabeto completo.
Con las máquinas el proceso de aprendizaje es en muchos casos muy similar. Lo que intentan los científicos de datos es que gracias a la repetición, a procesos de prueba y error o de obtención de «recompensas», los ordenadores aprendan patrones, sean capaces de reconocer características comunes de los objetos o reconozcan qué consecuencias se derivan de premisas similares. Para conseguirlo, los cienttíficos de datos intentan de automatizar algunas partes del método científico mediante técnicas matemáticas. En un plano teórico, podemos hablar de tres grandes aproximaciones al machine learning: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
Aprendizaje supervisado
En el aprendizaje supervisado, el objetivo es desarrollar un algoritmo que establezca una correspondencia entre los elementos de entrada y las distintas salidas deseadas. Las fuentes de entrada pueden ser, por ejemplo, fotografías de animales, mientras que las salidas serían en este caso las distintas etiquetas que los clasifican.
Para que el aprendizaje sea efectivo, se lleva a cabo lo que se conoce como «entrenar el modelo». Para ello, se determina en primer lugar el tipo de entrada que se va a utilizar y sus características comunes. Siguiendo con el ejemplo anterior, lo que nos puede interesar no es abarcar todo el reino animal, sino comenzar entrenando a nuestro futuro algoritmo con una tarea más sencilla, como puede ser aprender a reconocer un gato.
Para ello se reúne un «conjunto de entrenamiento» (miles de fotografías que contengan gatos) que se transforman en un vector de características que contienen sus propiedades comunes. Este conjunto debe ser lo suficiente grande como para predecir con precisión la salida y que de esta forma en el futuro, el algoritmo no confunda al gato con otros animales que se le pueden parecer, como puede ser el caso de un tigre, un lince u otro felino.
A continuación, se determina la estructura de la función adecuada para resolver el problema (una red neuronal artificial, un árbol de decisión, etc.). Finalmente, se complementa el diseño del modelo, de modo que a partir del elemento de entrada, el algoritmo descarta todas aquellas salidas que no corresponden con la etiqueta «Gato».
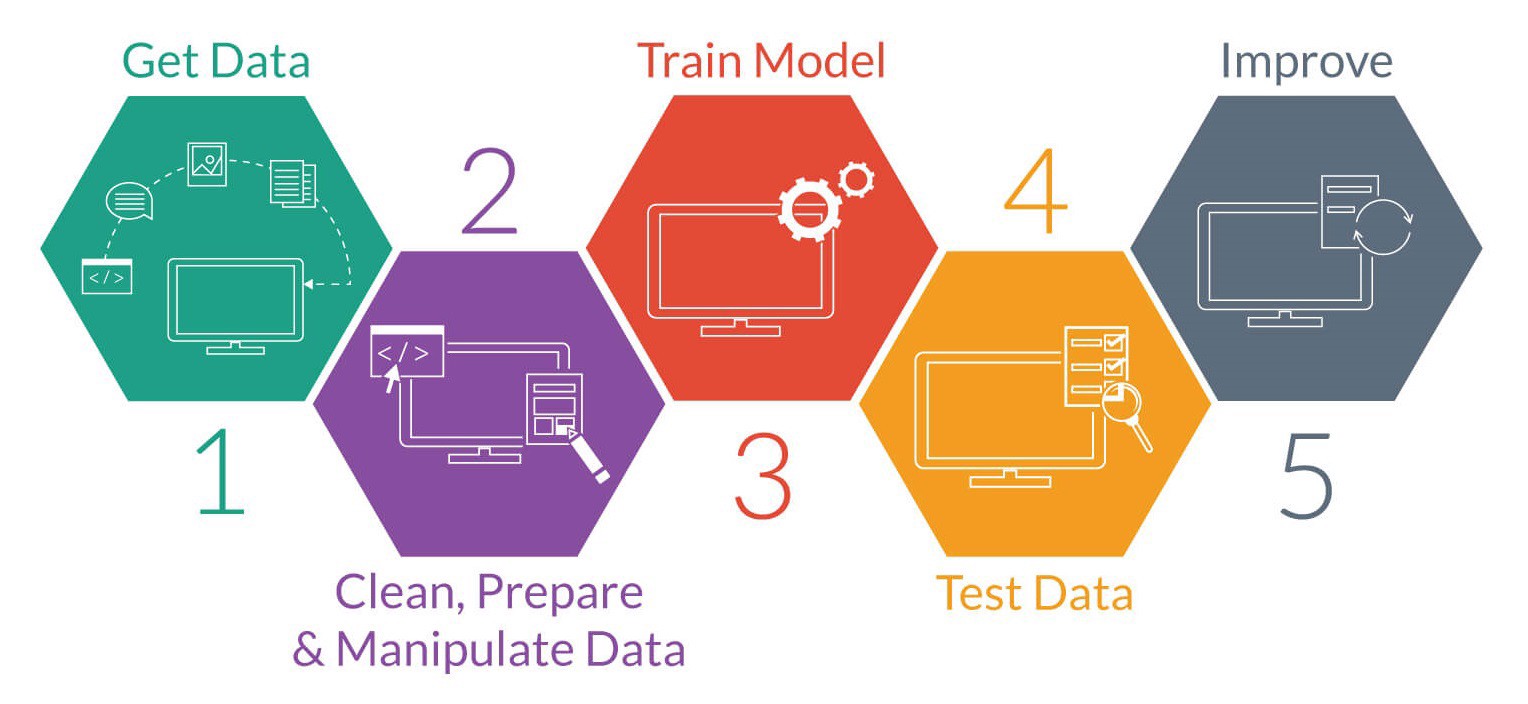
Proceso del método de aprendizaje supervisado
Aprendizaje no supervisado
En el aprendizaje no supervisado, todo el proceso de modelado se lleva a cabo utilizando conjuntos de ejemplos formados únicamente por entradas al sistema. En este caso no existe un conocimiento «a priori» de lo que es representado y se confía en que sea la propia IA la que determine sus características comunes.
Así, el aprendizaje no supervisado típicamente trata los objetos de entrada como un conjunto de variables aleatorias y es la red la que «descubre» de forma autónoma las características, regularidades, correlaciones y categorías de los datos. Dicho de otra forma, expuesta a millones de imágenes de lindos gatitos, la máquina debería tarde o temprano «aprender» cómo es un gato.
Por las propias limitaciones que este sistema impone, el aprendizaje no supervisado se emplea en proyectos menos complejos, ya que trata sobre todo de analizar componentes principales, agrupamiento y relación de características. En este sentido, este tipo de técnicas se usan con frecuencia en el sector financiero y bancario, donde potententes algoritmos se ocupan por ejemplo de encontrar inconsistencias en enormes volúmenes de datos.
Aprendizaje por refuerzo
El aprendizaje por refuerzo aplica la psicología conductista y se basa en un sistema de prueba y error basado en la obtención de «recompensas«.
En vez de que un instructor indique al algoritmo qué es lo que debe aprender, este «aprende» a comportarse en un entorno determinado, tomando unas reglas mínimas, en función a la recompensa que obtiene a cambio. El objetivo de este método es que el algoritmo reconozca las señales que le llevan a obtener la máxima recompensa y así optimizar su comportamiento tomando mejores decisiones.
Este tipo de técnicas es el ayudan a máquinas como Deep Blue ganar una partida de ajedrez a Garry Kasparov o a AlphaGo tumbar a a Lee Sedol, campeón del mundo de Go.
Además de estos tres métodos principales, en machine learning conviven otras técnicas, como el aprendizaje semisupervisado (combina las dos primeras), la tranducción (similar al supervisado) y el aprendizaje multi-tarea (utiliza el conocimiento ya «aprendido» por otro sistema para enfrentarse a problemas parecidos).
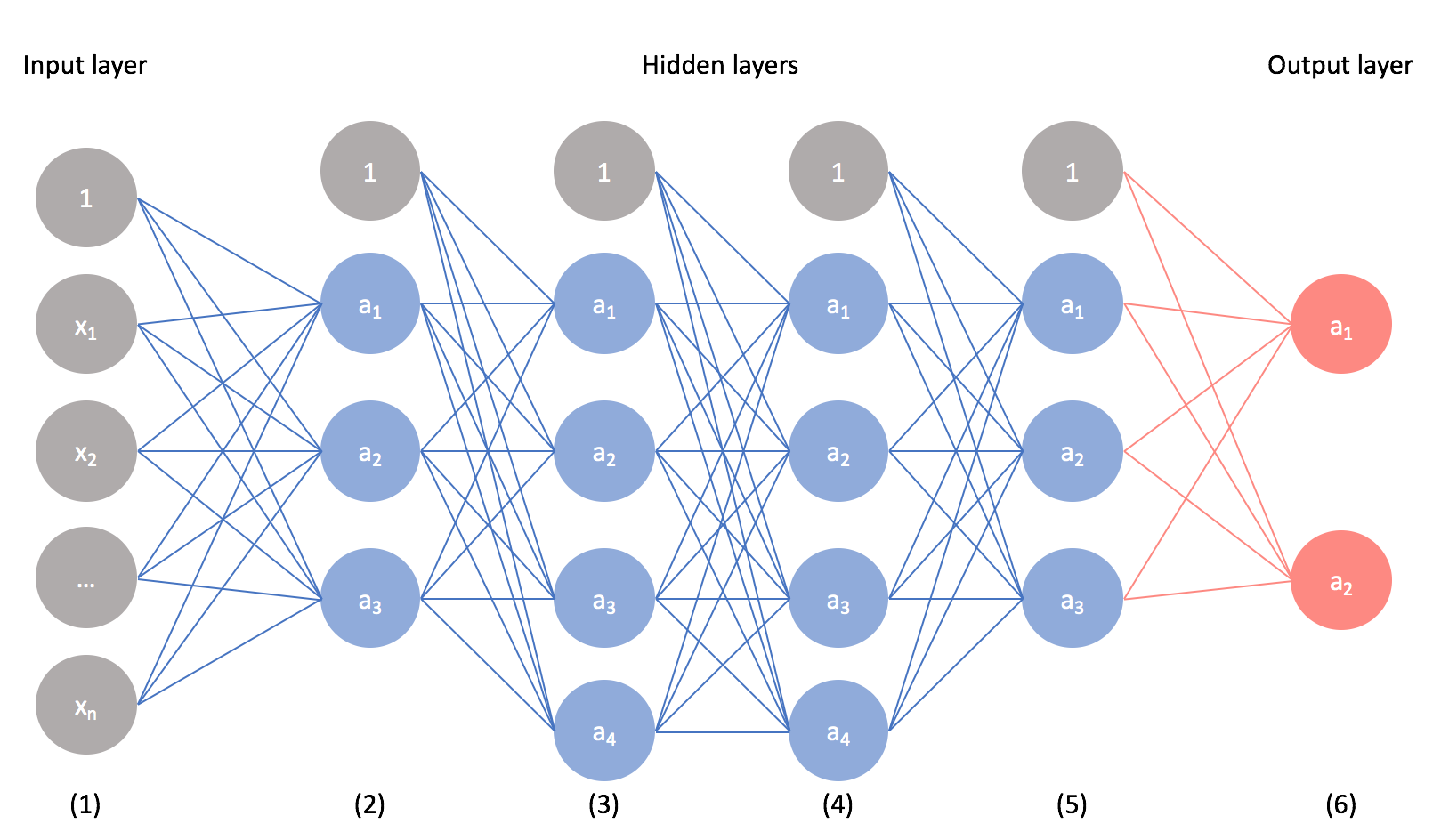
Esquema básico para una red neuronal artificial
Programando el algoritmo
Como hemos visto en los distintos métodos de aprendizaje, para enseñar a las máquinas a aprender, deberemos en primer lugar, determinar un modelo de algoritmo y en segundo término, contar con el software adecuado que nos permita desarrollarlo.
Entre los modelos más utilizados en este campo, destacan los que usan árboles de decisiones como modelo predictivo, reglas de asociación que tienen como objetivo descubrir relaciones interesantes entre variables, redes neuronales artificiales inspiradas en los sistemas nerviosos de los animales, máquinas de vectores de soporte o redes bayesianas para la representación de relaciones probabilísticas, entre otros métodos.
A la hora de implementar estos algoritmos, existen un buen número de lenguajes de programación que facilitan enormemente esta tarea. Hasta hace unos años, los más populares en este campo eran Python y R, un lenguaje de programación estadístico con numerosas bibliotecas relacionadas con machine learning.
En los últimos años sin embargo se han disparado las alternativas, siendo Tensor Flow una de las más utilizadas. Nacido en las entrañas de Google y liberado en 2015 como proyecto Open Source, se basa en una serie de librerías que utilizan un sistema de aprendizaje automático basado en redes neuronales de aprendizaje profundo.
Otras opciones conocidas en este terreno son Apache Spark, RapidMiner, OpenNN o MATLAB.Además compañías como Microsoft (Azure Machine Learning) u Oracle (Oracle Data Mining) se han esforzado en poner en manos de las compañías sus propias soluciones.
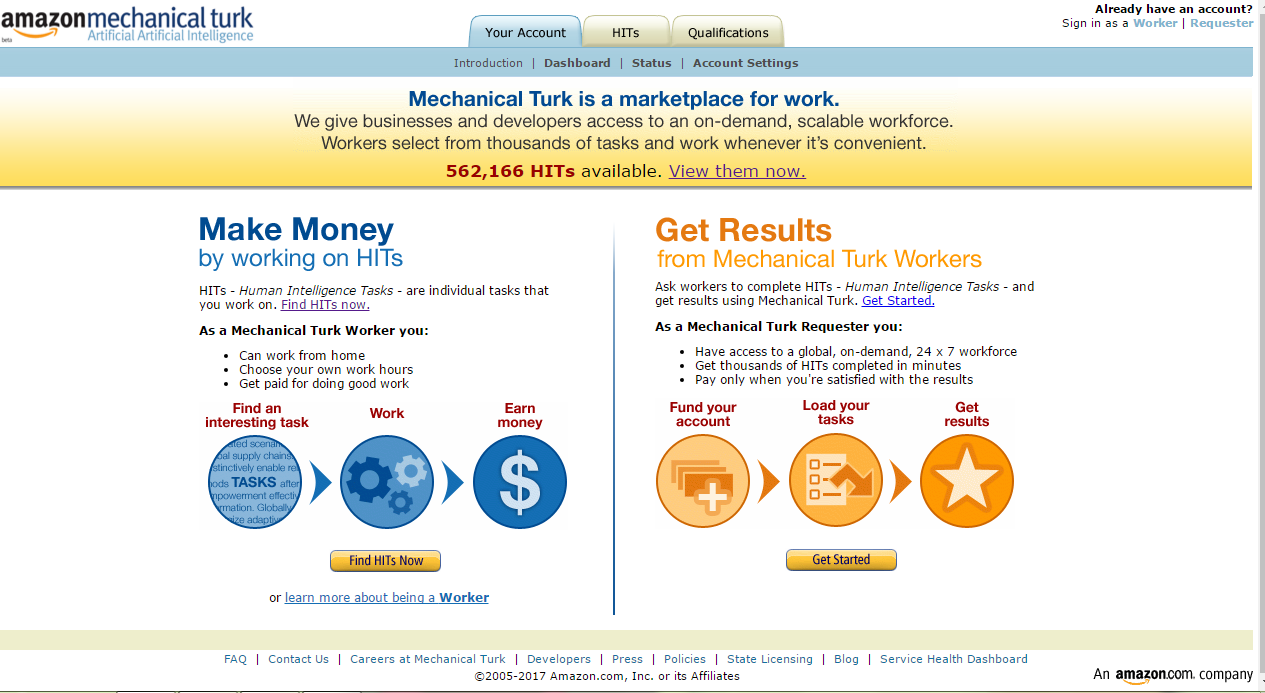
Human Intelligence Tasks: cuando la máquina no basta
Especialmente al emplear el método de «aprendizaje supervisado» hay muchos escenarios en los que utilizar un «simple algoritmo» no basta. Si volvemos al ejemplo de los animales, sobre el papel parece sencillo enseñar a una máquina qué es un gato y en qué se diferencia de un perro. Sin embargo resulta muchísimo más difícil explicarle qué es una imagen violenta, si un desnudo es o no una obra de arte, analizar opiniones, o en tiempos de fake news, interpretar si una noticia es verdadera o falsa.
Para estas tareas, grandes empresas tecnológicas como Amazon, Facebook o Google emplean a miles de personas en todo el mundo cuya misión es precisamente esa: enseñar a las máquinas. Mientras que algunas como Facebook utilizan esta fuerza humana para mejorar su propio algoritmo, otras las ponen además a disposición de otras empresas. La más popular en este campo es sin lugar a dudas Amazon Mechanical Turk.
La plataforma se presenta como un marketplace en el que las empresas plantean todo tipo de micro-trabajos (HITS) que no pueden realizados de forma sencilla por una máquina, como reconocer el contenido de un grupo de imágenes, transcribir audios, normalizar los datos y encuestas, etc. En el otro lado de la cadena están los «turkers», normalmente freelancers que compiten por todo tipo de HITS y que pasan su jornada laboral pendientes de los trabajos mejor pagados.
Por cada HIT completado y en función de su dificultad (normalmente el tiempo medio empleado) el turker recibe una compensación económica que va desde los pocos céntimos a dos o tres dólares. Ser un turker como veis no es precisamente un chollo y de hecho varias veces se han denunciado unas condiciones de trabajo que son muy mejorables. Alternativas populares a la propuesta de Amazon son Crowdsource, Figure Eight o JobBoy.
El futuro del Machine Learning
¿Cómo va ser el machine learning del futuro? ¿Cuál es el límite de aprendizaje que tienen las máquinas? ¿Además de conocimientos, los ordenadores pueden «aprender emociones»? Son algunas de las preguntas que en estos momentos se están planetando los científicos de datos.
Campos como el entendimiento natural del lenguaje, o que los ordenadores sean capaces no tanto de interpretar sino de generar conocimientos nuevos son dos de los campos en los que más investigaciones se están desarrollando en estos momentos. Es posible que dentro de unos años las máquinas sean capaces de llegar a conclusiones mayores en periodos de tiempo mucho menores, superando incluso la capacidad humana para procesar conocimientos. O puede que necesitamos desarrollar nuevos frameworks que realmente sean capaces de generar redes neuronales auténticamente inteligentes. El futuro en cualquier caso, promete.








HPE demanda al grupo chino Inspur por violación de patentes y prácticas engañosas

Linux Foundation lanza Open Platform for Enterprise AI para crear herramientas de IA generativa open source

«El low code en sí no es una tecnología o una plataforma, es una estrategia»

Huawei muestra su potencial para empresas y cloud en España en el Digital Transformation Summit

Cinco estrategias para mejoras la experiencia del cliente que compra on-line

El Congreso Aslan revalida su posición como cita tecnológica de referencia

Dynatrace Carbon Impact, solución para reducir la huella de carbono en la empresa

Red Hat e Inetum automatizan la infraestructura TIC de Madrid Digital

Cómo la tecnología mejora el día a día en un quirófano

NTT DATA acelera la implementación del 5G ORAN usando la tecnología de Red Hat

¿Más datos significa más riesgo?

Educación y tecnologías: ¿cuáles se han impuesto en las aulas?
HPE demanda al grupo chino Inspur por violación de patentes y prácticas engañosas
¿Más datos significa más riesgo?

Lenovo ThinkPad L Series y X Series: más innovación, más sostenibilidad

Cómo elegir el switch ideal para una empresa

Multa de 250 millones a Google por incumplir sus acuerdos con los medios de Francia
Zoom anuncia Compliance Manager, una plataforma de compliance de las comunicaciones
-

 EntrevistasHace 2 días
EntrevistasHace 2 días«No tiene sentido una estrategia tecnológica que no encaje al 100% con la del CEO»
-

 RecursosHace 4 días
RecursosHace 4 díasCuatro mitos del Mac en la empresa que tienes que desterrar
-

 NoticiasHace 4 días
NoticiasHace 4 díasBeDisruptive y el CCI acuerdan trabajar para reforzar la ciberseguridad industrial en España
-

 NoticiasHace 3 días
NoticiasHace 3 díasIberdrola, en busca de socios para construir centros de datos