Noticias
NVIDIA quiere integrar varias GPUs en una solución multichip, todo lo que debes saber

Las nuevas generaciones de tarjetas gráficas que han ido llegando al mercado han experimentado un aumento considerable de potencia que llega a superar al que ofrecen varias GPUs basadas en arquitecturas anteriores.
Un ejemplo claro lo tenemos en las GTX 1080 TI, que es capaz de rendir al mismo nivel que dos GTX 980. Esto ha sido posible gracias a los cambios de arquitectura y a las reducciones de proceso, que han permitido integrar un mayor conteo de shaders en un único encapsulado sin comprometer consumos ni temperaturas.
Sin embargo la situación se está volviendo cada vez más complicada, ya que nos acercamos a los límites del silicio y fabricar chips de gran tamaño no es una alternativa rentable por el impacto que tienen en la superficie de las obleas de silicio. Sobre este tema ya os hablamos en este artículo, así que os recomendamos echarle un ojo antes de seguir leyendo.
El caso es que un documento científico ha confirmado que NVIDIA está considerando dar el salto a las soluciones multichip para integrar varias GPUs en un único encapsulado. Con esta medida podría superar los desafíos que plantea el incremento de potencia bajo el tradicional sistema de cambios de arquitectura y reducción de proceso sobre una única GPU.
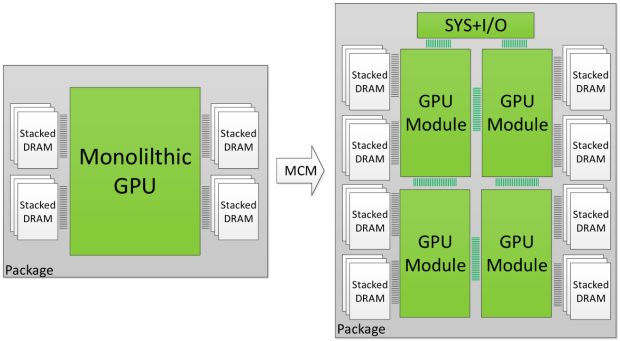
La idea es parecida a lo que vimos en la Tesla K80 con doble GPU, y consisten en montar varios chips en un mismo PCB para aumentar la potencia bruta de la tarjeta gráfica sin recurrir a configuraciones multiGPU tradicionales.
Es interesante pero plantea un problema claro, y es que no es nada fácil distribuir de forma eficiente la carga de trabajo entre varias GPUs, un obstáculo que también afecta como sabemos a los procesadores de propósito general que utilizan varios núcleos.
Se comenta que para resolver esta cuestión NVIDIA podría apostar por utilizar varias GPUs de menor rendimiento y por tanto más pequeñas y eficientes, que estarían integradas en un único encapsulado y que contarían con conexiones de alta velocidad que les permitirían actuar como si fueran una única unidad de procesamiento gráfico.
De momento sólo tenemos datos de simulaciones que demuestran que es un enfoque prometedor, y de hecho AMD también quiere seguir ese camino con sus GPUs Navy, pero todavía queda mucho camino por recorrer y muchas preguntas que resolver.
Más información: Techreport.







¿Puede la RAM china bajar los precios de las memorias?

OpenAI prepara su gran salto al hardware

IA y tecnología contra incendios forestales

El Galaxy Z TriFold regresará con más ambición

Apple AI glasses: menos Vision Pro, más IA, 2027

Nuevo driver GeForce Game Ready y novedades RTX de la semana

Qué es HDR y cómo mejora la experiencia en juegos o vídeos

Cómo actualizar Windows mediante el Catálogo de Microsoft Update

Qué es un SoC y por qué es tan importante en la industria de los semiconductores

¿Qué ha pasado con ChatGPT? Dos fallos preocupantes

Ford Capri RWD, asentamiento

Galaxy Z Fold8, Fold8 Ultra y Flip8 ya son oficiales
¿Puede la RAM china bajar los precios de las memorias?

La UE impone una multa millonaria a AliExpress por incumplir la Ley de Servicios Digitales
Cómo actualizar Windows mediante el Catálogo de Microsoft Update

Francia prohíbe a menores de 15 años el acceso a redes sociales
Galaxy Z Fold8, Fold8 Ultra y Flip8 ya son oficiales

Microsoft amplía su programa de compatibilidad de juegos Xbox en PC

-
 GuíasHace 6 días
GuíasHace 6 díasQué es HDR y cómo mejora la experiencia en juegos o vídeos
-
 PrácticosHace 7 días
PrácticosHace 7 díasCómo actualizar Windows mediante el Catálogo de Microsoft Update
-
 A FondoHace 2 días
A FondoHace 2 díasQué es un SoC y por qué es tan importante en la industria de los semiconductores
-
 NoticiasHace 6 días
NoticiasHace 6 días¿Qué ha pasado con ChatGPT? Dos fallos preocupantes