Noticias
Rendimiento multiGPU cruzado con soluciones GTX y Radeon

Uno de los grandes atractivos que plantea DirectX 12 son las mejoras de rendimiento gracias a la introducción de nuevas tecnologías, como los shaders asíncronos, por ejemplo, y también gracias al uso de APIs de bajo nivel que permiten un mayor aprovechamiento de todos los recursos del sistema.
Ya hemos podido ver los beneficios de todo esto en Xbox One y PS4, consolas que a pesar de su baja potencia comparada con un PC de gama alta disfrutan de la optimización que permite conseguir dichas herramientas.
Dicho esto no podemos olvidarnos de las bondades que plantea también el uso de configuraciones multiGPU en DirecX 12, siendo posible no sólo sumar la memoria de vídeo de las tarjetas gráficas, sino además utilizar soluciones de fabricantes distintos.
Así, es posible usar una GTX y una Radeon en modo multiGPU, aunque como vemos los resultados que conseguimos son bastante dispares, y dejan claros algunos detalles importantes que debemos tener muy en cuenta.
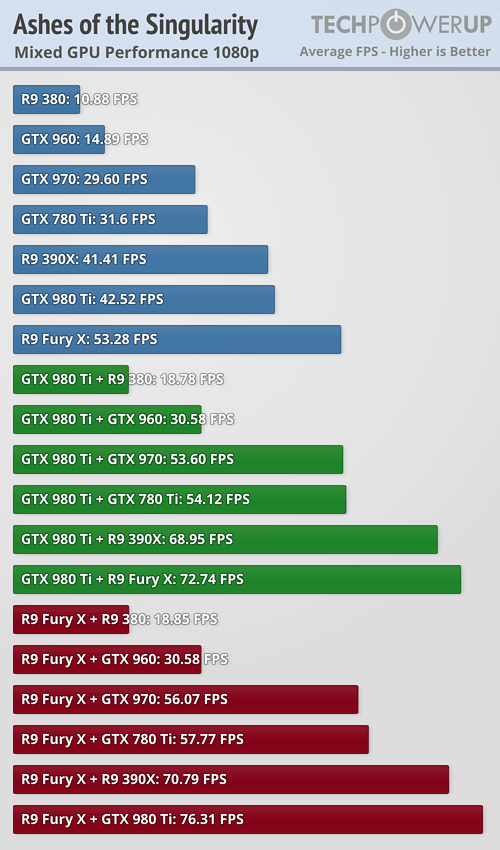
Por un lado salta a la vista que la tarjeta gráfica más lenta influye drásticamente en el rendimiento final, lo que supone que utilizar configuraciones como una GTX 980 Ti y una GTX 960 no sea nada recomendable.
Esto nos lleva al siguiente punto, y es que la tarjeta más potente debe ser utilizada como maestra, ya que también influye bastante en el rendimiento, aunque como podemos ver en general el escalado resulta bastante pobre.
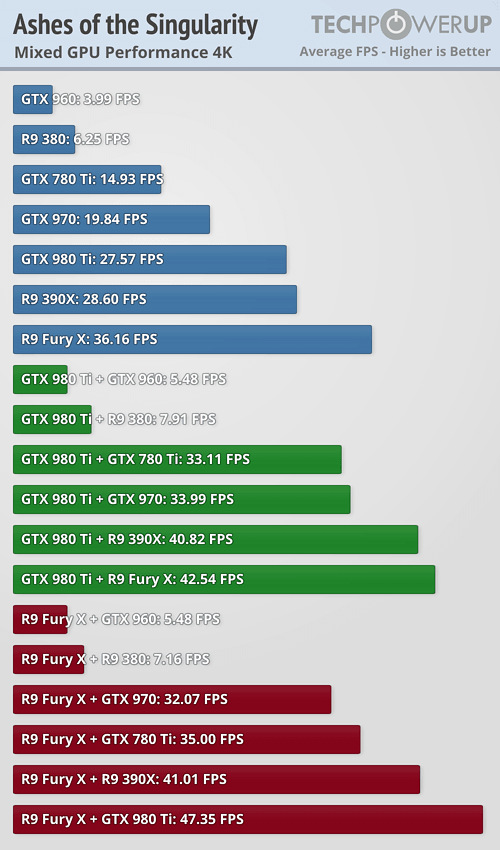
Podemos concluir que todavía queda mucho camino por recorrer, y que las primeras pruebas no son del todo alentadoras.
Más información: TechPowerUP!













El Galaxy Z TriFold regresará con más ambición

Apple AI glasses: menos Vision Pro, más IA, 2027

Nuevo driver GeForce Game Ready y novedades RTX de la semana

Ofertas por la vuelta al cole en PCSpecialist en PCs y portátiles

Radeon RX 9050: especificaciones completas

GTA VI y la sombra del downgrade gráfico: hay miedo, y está justificado

Qué es HDR y cómo mejora la experiencia en juegos o vídeos

Cómo actualizar Windows mediante el Catálogo de Microsoft Update

Qué es un SoC y por qué es tan importante en la industria de los semiconductores

FluentCleaner Classic: el sueño del Windows ligero a golpe de clic y desde el código abierto

Ya sabemos precios del Acer Predator Atlas 8 y no te van a gustar

¿Qué ha pasado con ChatGPT? Dos fallos preocupantes
El Galaxy Z TriFold regresará con más ambición
Ya sabemos precios del Acer Predator Atlas 8 y no te van a gustar
FluentCleaner Classic: el sueño del Windows ligero a golpe de clic y desde el código abierto

Ford Capri RWD, asentamiento

La UE impone una multa millonaria a AliExpress por incumplir la Ley de Servicios Digitales
Cómo actualizar Windows mediante el Catálogo de Microsoft Update

-
 GuíasHace 5 días
GuíasHace 5 díasQué es HDR y cómo mejora la experiencia en juegos o vídeos
-
 PrácticosHace 6 días
PrácticosHace 6 díasCómo actualizar Windows mediante el Catálogo de Microsoft Update
-
 A FondoHace 2 días
A FondoHace 2 díasQué es un SoC y por qué es tan importante en la industria de los semiconductores
-
 NoticiasHace 7 días
NoticiasHace 7 díasFluentCleaner Classic: el sueño del Windows ligero a golpe de clic y desde el código abierto