Noticias
Intel y AMD utilizarán hardware dedicado en sus CPUs para acelerar IA

Hay muchas maneras de acelerar cargas de trabajo de IA a nivel de hardware. No hay duda de que la gran estrella a día de hoy es la GPU, pero Intel y AMD están buscando la manera de hacer que sus CPUs puedan sacar adelante de forma eficiente con ciertas cargas de trabajo relacionadas con la IA.
Sé lo que estáis pensando, que para eso tenemos la NPU, y no os falta razón, pero en este caso lo que Intel y AMD quieren es que la aceleración se produzca dentro del propio procesador. Para conseguirlo, ambas compañías han creado ACE, siglas de «Advance Compute Extensions», una especificación que busca superar los límites de AVX10.
Es importante tener en cuenta que las instrucciones AVX no nacieron para sacar adelante cargas de trabajo de multiplicación de matrices, que son la base de la IA, pero estas han servido de puente para introducir ACE, ya que este estándar mantiene la estructura de registro vista en AVX10, y añade hardware dedicado para resolver operaciones con matrices.
De esta manera se evita obligar a los desarrolladores a utilizar formatos de datos o modelos de programación totalmente nuevos, ya que las extensiones seguirán utilizando entradas de 512 bits, y con ello se reducirán al mínimo los cambios necesarios para poder adoptar y utilizar ese nuevo estándar a gran escala.
En cuanto a las mejoras de rendimiento, a nivel de instrucciones tenemos que con un conjunto dado de vectores de entrada ACE puede realizar hasta 16 veces más operaciones que AVX10. Esta diferencia es abismal, aunque es importante tener en cuenta que los resultados finales pueden variar en función de cada escenario y de cada prueba.
ACE también es interesante por lo que supone en términos de eficiencia. No puede alcanzar el nivel de rendimiento que tendríamos con una GPU de última generación, pero como contrapartida su consumo energético es mucho más bajo, lo que hace que este estándar sea viable, y muy interesante, en cargas de trabajo de IA en el borde, y también para cubrir las necesidades de usuarios individuales.
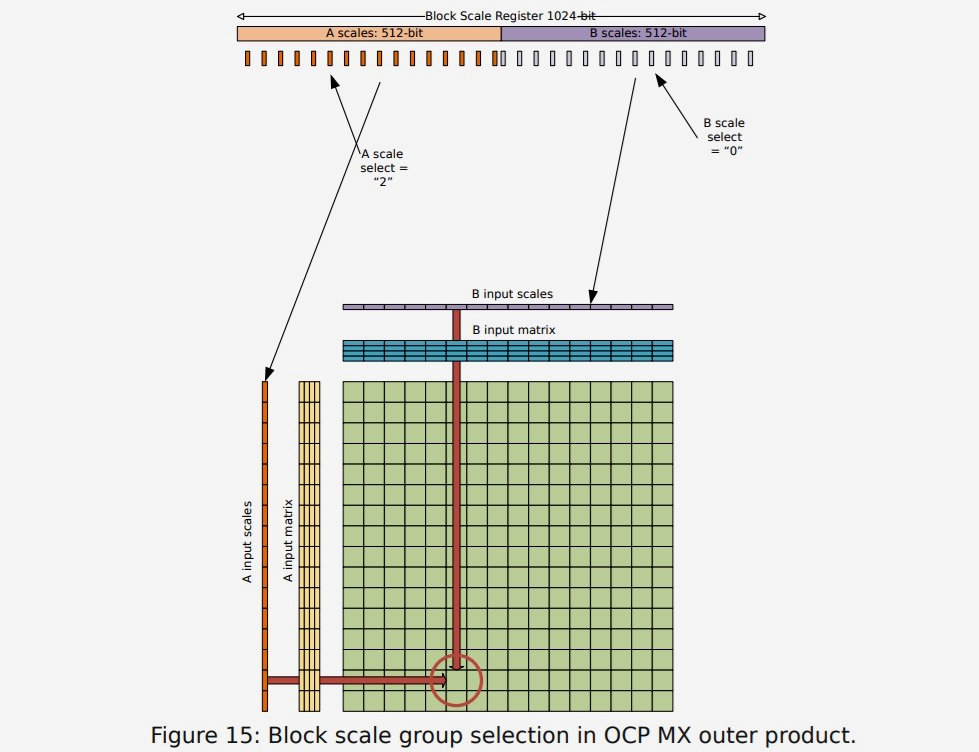
Este nuevo estándar se podrá implementar de manera agnóstica, lo que permitirá conseguir una mayor consistencia, y soportará una gran variedad de tipos de operaciones, incluyendo: INT8, INT32, FP8, FP16, FP32 y BF16. Tendrá también soporte nativo para formatos de bloques a escala MX del Open Compute Project, que no están soportados bajo AVX10, lo que se traduce en una gran versatilidad.
¿Y por qué adoptar ACE si tenemos NPUs? Pues muy sencillo, porque ACE es una apuesta más sencilla y eficiente que encaja perfectamente en la computación heterogénea, y evita todas las complicaciones que puede suponer tener que mover ciertas cargas de trabajo a una NPU. Dichas cargas se pueden ventilar directamente en la CPU con una mayor simplicidad y eficiencia.













Intel y AMD utilizarán hardware dedicado en sus CPUs para acelerar IA

Steam Machine rinde peor que PS5 y cuesta el doble

Valve trabaja con NVIDIA para dar soporte en SteamOS a sus tarjetas gráficas

Descubre el Lefant M5 Pro: un robot de limpieza para usuarios exigentes con un 70% de descuento

Samsung presenta su almacenamiento UFS 5.0 para potenciar la IA móvil

Consigue los mini PCs de GEEKOM al precio más bajo del año durante el Amazon Prime Day

Qué procesador necesito para cada tarjeta gráfica: guía actualizada a 2026

Cómo mejorar el rendimiento del Explorador de archivos de Windows

El nuevo Rufus 4.15 automatiza como nunca la instalación de Windows 11

GEEKOM A5 Pro por solo 374 euros y descuentos de hasta 550 euros: precios más bajos que en Amazon Prime Day

Primeros datos de rendimiento de la Steam Machine de Valve

Silent Hill de 1999 llega a PC de forma nativa, y funciona al 100%
Intel y AMD utilizarán hardware dedicado en sus CPUs para acelerar IA

El iPhone 18 llegará en 2027, ¿por qué lo ha retrasado Apple?

Adobe renueva Creative Cloud: más IA, menos tareas repetitivas

Cuánto ha subido la memoria RAM en un año?

KIOXIA EXCERIA G3 4 TB: más espacio para una Gen5 más accesible

Qualcomm presenta el Snapdragon Reality Elite para visores y gafas inteligentes

-
 GuíasHace 6 días
GuíasHace 6 díasQué procesador necesito para cada tarjeta gráfica: guía actualizada a 2026
-
 PrácticosHace 4 días
PrácticosHace 4 díasCómo mejorar el rendimiento del Explorador de archivos de Windows
-
 NoticiasHace 5 días
NoticiasHace 5 díasEl nuevo Rufus 4.15 automatiza como nunca la instalación de Windows 11
-
 NoticiasHace 3 días
NoticiasHace 3 díasGEEKOM A5 Pro por solo 374 euros y descuentos de hasta 550 euros: precios más bajos que en Amazon Prime Day