A Fondo
NVIDIA RTX y AMD Radeon: ¿Por que gana NVIDIA en trazado de rayos? La clave está en la arquitectura

El trazado de rayos se ha convertido en el presente de los videojuegos, gracias a la apuesta que han realizado los grandes del sector, NVIDIA y AMD, y al creciente apoyo que esta tecnología está recibiendo por parte de los desarrolladores. En este sentido, es importante destacar que el soporte de dicha tecnología en las consolas de nueva generación, PS5 y Xbox Series X-Series S, también está siendo clave para favorecer su adopción.
Los que nos leéis a diario ya sabéis qué es el trazado de rayos, cómo funciona y qué supone para el mundo de los videojuegos. En este artículo hicimos un análisis profundo con todas sus claves, vimos por qué es tan importante y descubrimos sus mecánicas, es decir, el modelo de rayos, impacto-fallo y colisiones, tres aspectos que son fundamentales a la hora de explicar el enorme impacto que tiene esta tecnología a nivel de rendimiento.
Durante los últimos meses también hemos visto diferentes pruebas de rendimiento, utilizando tarjetas gráficas RTX de NVIDIA y Radeon RX 6000 de NVIDIA en juegos preparados para aprovechar, de una forma u otra, el trazado de rayos, y la conclusión a la que hemos llegado ha sido muy clara: NVIDIA lleva la delantera, y de una manera bastante clara.
Sin embargo, sé que muchos de nuestros lectores no terminan de entender por qué hay una diferencia tan grande de rendimiento, en trazado de rayos, entre las tarjetas gráficas RTX 30 de NVIDIA y las RX 6000 de AMD, y por eso he decidido compartir con vosotros un artículo, donde vamos a responder a esa pregunta. Como siempre, si tras leer este artículo tenéis dudas, podéis dejarlas en los comentarios.

Metro Exodus Enhanced Edition con trazado de rayos al máximo.
Trazado de rayos: Consideraciones previas
La carga de trabajo que supone el trazado de rayos es la misma, con independencia del tipo de arquitectura que utilicemos. Calcular las intersecciones y las colisiones de los rayos es la base de dicha tecnología, y representa una «piedra muy pesada» que, en aquellas tarjetas gráficas que carecen de hardware especializado, tiene que calcularse a través de los shaders.
El estrés añadido que supone el trazado de rayos aplicado a una GPU sin hardware especializado es tan grande que esta no puede, salvo casos muy concretos, ofrecer un rendimiento mínimamente aceptable. No es complicado de entender, los mismos elementos del núcleo gráfico tienen que ocuparse de las tareas clásicas de rasterización, y a esto se añaden las intersecciones y las colisiones, lo que representa un consumo enorme de recursos, y eleva los milisegundos necesarios para generar cada fotograma.
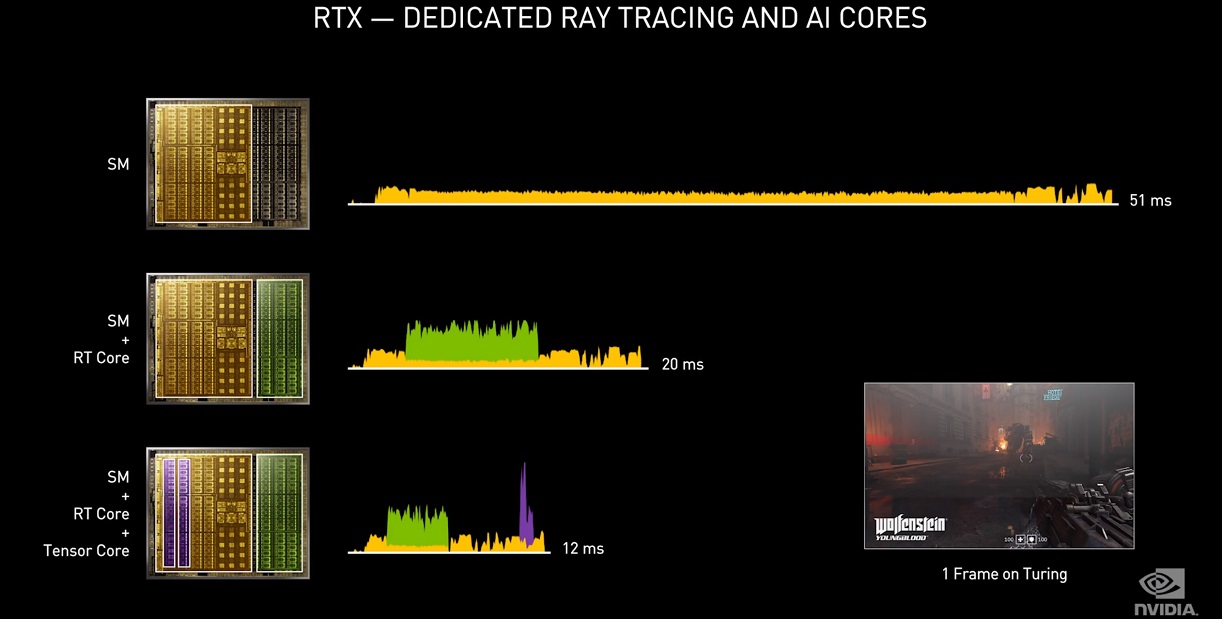
Así, por ejemplo, para generar un fotograma por segundo sin hardware especializado, recurriendo únicamente a los shaders, podríamos registrar un tiempo de 51 milisegundos, mientras que combinando shaders y núcleos RT ese tiempo se reduciría a 20 milisegundos. Si añadimos los núcleos tensor, presentes en las soluciones gráficas de NVIDIA, el tiempo bajaría a 12 milisegundos.
Bien, ¿qué quieren decir esas cifras? Pues es muy simple, para mantener 30 fotogramas por segundo la GPU debe renderizar cada fotograma en 33,33 milisegundos, y si queremos mantener 60 fotogramas por segundo ese tiempo se reduce a tan solo 16,66 milisegundos. Con un tiempo de renderizado de 51 milisegundos, el rendimiento sería terrible, mientras que con un tiempo de 20 milisegundos podríamos jugar con fluidez, y con un tiempo de 12 milisegundos la experiencia sería totalmente óptima.
El hardware dedicado a acelerar trazado de rayos saca adelante tareas propias de dicha tecnología para reducir, en definitiva, el tiempo necesario para generar cada fotograma, pero tanto NVIDIA como AMD han seguido enfoques diferentes, y esto ha hecho que su rendimiento real sea muy distinto.
AMD y trazado de rayos: Una aproximación limitada
Empezamos con AMD. Cuando NVIDIA confirmó su apuesta por el trazado de rayos allá por 2018, la compañía de Sunnyvale decidió esperar a que dicha tecnología empezase a estandarizarse. Esto hizo que las Radeon RX 5000 llegasen al mercado sin hardware dedicado para acelerar trazado de rayos, lo que las colocó, desde una perspectiva tecnológica, en una posición de clara inferioridad frente a las RTX 20.
Las Radeon RX 6000 se convirtieron, por tanto, en la primera generación de tarjetas gráficas de AMD en contar con hardware dedicado para acelerar trazado de rayos. Cuando Microsoft habló de la tecnología que había detrás del SoC de Xbox Series X pudimos confirmar cómo había implementado AMD el hardware dedicado a trazado de rayos en su arquitectura RDNA 2, y desde entonces mis expectativas se redujeron de forma notable, y mis previsiones no fueron nada buenas. Al final acerté en casi todo lo que comenté en este sentido.
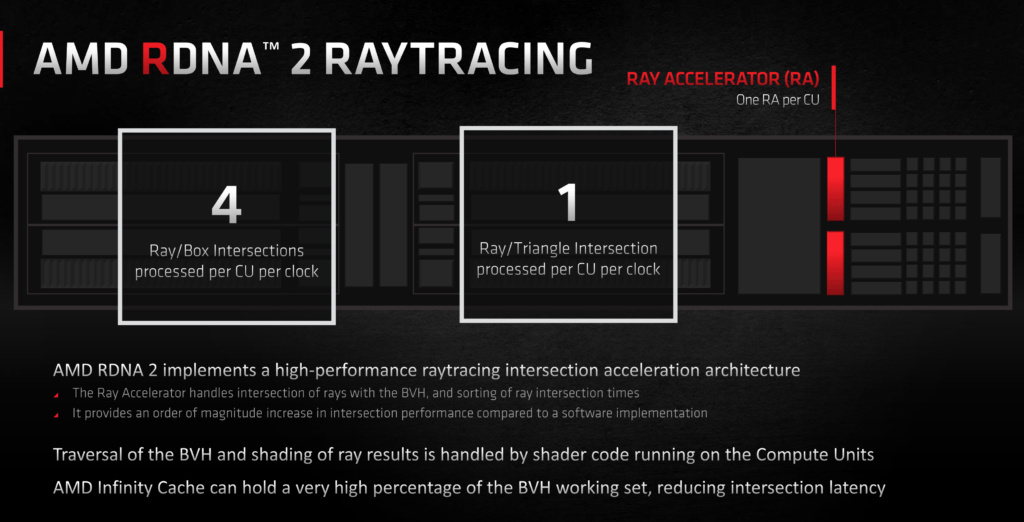
En la arquitectura RDNA 2, la base de las Radeon RX 6000, tenemos una unidad de aceleración de trazado de rayos por cada unidad de computación. Una unidad de computación tiene 64 shaders y 4 unidades de texturizado, pero dicha unidad de aceleración de trazado de rayos comparte recursos con los motores de texturizado, lo que significa que no pueden trabajar de forma simultanea.
A todo lo anterior, debemos añadir, además, otras dos limitaciones importantes que presentan esas unidades de aceleración de trazado de rayos. La primera, y la más importante, es que esas unidades de aceleración de trazado de rayos trabajan con las intersecciones rayo-triángulo y con las delimitadoras de cuadro, que son las más intensivas y las que más recursos consumen, pero las intersecciones transversales BVH, que son un paso previo a aquellas, corren a cargo de los shaders.

Trazado de rayos en Cyberpunk 2077
Es posible reducir el impacto de las intersecciones transversales BVH mediante optimizaciones concretas en juegos para reducir el tiempo de renderizado, pero no siempre resulta viable, y cuando no se hace, o no se ejecuta de forma adecuada, la pérdida de rendimiento es notable, ya que se consumen recursos muy valiosos que podrían haberse dedicado a tareas de sombreado. Su segunda limitación es que carecen de la capacidad de trabajar de forma asíncrona.
¿Y por qué ha utilizado AMD este diseño en sus Radeon RX 6000? Creo que porque era la más efectiva en términos de coste y de espacio en el chip. No debemos olvidar que RDNA 2 es una arquitectura que fue diseñada para convertirse en el pilar central de las consolas de nueva generación, y que estas utilizan APUs, una solución donde el espacio en el chip no solo es muy limitado, sino que además se reparte entre la CPU y la GPU.
Dedicar mucho espacio a integrar hardware especializado en trazado de rayos no era una opción viable, sobre todo cuando has doblado el máximo de shaders, y has decidido recurrir a la caché infinita para mejorar el ancho de banda sin tener que recurrir a buses de más de 256 bits, ni a memorias de más de 16 GHz. La caché infinita ocupa mucho espacio en el chip, aunque al mismo tiempo su presencia está justificada, no solo por lo que hemos dicho, sino también porque, bien utilizada, puede ayudar a mejorar el rendimiento en trazado de rayos, ya que ciertas cargas tienen una dependencia mínima de la capacidad, y una dependencia enorme del ancho de banda.
Arquitectura Turing
NVIDIA: Ampere consagró, e impulsó, las bases de Turing
La aproximación de NVIDIA es totalmente distinta a la de AMD. El gigante verde integró los núcleos RT como un tipo de hardware dedicado a descargar por completo a los shaders de las tareas del trazado de rayos. Esto quiere decir que cada núcleo RT calcula las intersecciones transversales BVH, las intersecciones rayo-triángulo, las intersecciones delimitadoras de cuadro y el sistema de colisiones. En el caso de los núcleos RT presentes en Ampere (RTX 30), estos calculan también la interpolación de cada triángulo en el tiempo.
Cada unidad SM tiene 64 shaders, 4 unidades de texturizado y un núcleo RT en Turing, y 128 shaders, 4 unidades de texturizado y un núcleo RT en Ampere. Estos núcleos no comparten recursos con los motores de texturizado, pueden trabajar de forma totalmente independiente y asíncrona, de manera que, cuando la unidad SM lanza un rayo, los núcleos RT se ocupan de sacar adelante todo el proceso de acierto fallo, así como las colisiones. Este trabajo se puede realizar de forma asíncrona, como hemos dicho, lo que permite al programador de tareas ordenar la realización de todo el trabajo relacionado con el trazado de rayos, las cargas de computación y gráficos y, si procede, el trabajo de los núcleos tensor, de forma simultánea.

Arquitectura Ampere
En la arquitectura Ampere, renderizar un fotograma con trazado de rayos por software mediante los shaders requiere de 37 milisegundos. Con el apoyo de los núcleos RT, el tiempo se reduce a 11 milisegundos, y si aplicamos además los núcleos tensor el tiempo baja a 6,7 milisegundos. Son cifras verdaderamente impresionantes que confirman que NVIDIA ha logrado «domar» el trazado de rayos con Ampere, aunque creo que lo más interesantes está por venir, y que con las RTX 40 veremos un salto mucho más grande.

Cyberpunk 2077 con trazado de rayos
Os recuerdo, antes de terminar, que NVIDIA también utiliza los núcleos tensor para sacar adelante una parte importante de la carga de trabajo que representa el trazado de rayos, la reducción de ruido, uno de los pasos finales, y de los más importantes, que se realizan para completar el renderizado de cada fotograma. Sin este, las imágenes llegarían cargadas de ruido, y tendrían un aspecto sucio y deslucido. No debemos olvidar, además, que los núcleos tensor permiten activar la tecnología DLSS de NVIDIA, una técnica de reconstrucción inteligente que reduce el número de píxeles sin pérdida de calidad de imagen, y que aligera, de esta manera, la carga que supone el trazado de rayos.
AMD está trabajando en su propia alternativa, conocida provisionalmente como FidelityFX Super Resolution, aunque todavía no sabemos de qué será realmente capaz, y tampoco tenemos una fecha de lanzamiento confirmada, así que toca esperar. Con todo, y viendo lo que consiguió NVIDIA con la primera generación de DLSS, es probable que esa tecnología de AMD necesite de una revisión para terminar de madurar.










Los mejores contenidos de la semana en MuyComputer (DXXXIV)

Apple prepara su primer iPad resistente al agua

Incendios forestales: las mejores herramientas para estar informado

Recursos online imprescindibles para tus vacaciones

WhatsApp estrena cuatro novedades muy útiles

OpenAI afronta una fractura por la regulación

Qué es HDR y cómo mejora la experiencia en juegos o vídeos

Cómo actualizar Windows mediante el Catálogo de Microsoft Update

Cómo acelerar el arranque de Windows sin usar software externo

Ocho funciones de Windows que puedes desactivar para mejorar la seguridad de un PC

Lenovo lanza el portátil económico Lecoo Pro 14

FluentCleaner Classic: el sueño del Windows ligero a golpe de clic y desde el código abierto
Los mejores contenidos de la semana en MuyComputer (DXXXIV)

GIGABYTE AORUS PRIME 3 análisis completo
El Google Pixel 11a llega en agosto abaratando precios

ASUS Pad, un tablet para dominar la gama media

Los 5 mejores mini PCs de GEEKOM que puedes comprar ahora mismo, y con descuento

La GeForce GTX 1060 cumple 10 años: una de las mejores gama media de la historia

-
 GuíasHace 3 días
GuíasHace 3 díasQué es HDR y cómo mejora la experiencia en juegos o vídeos
-
 PrácticosHace 4 días
PrácticosHace 4 díasCómo actualizar Windows mediante el Catálogo de Microsoft Update
-
 PrácticosHace 7 días
PrácticosHace 7 díasCómo acelerar el arranque de Windows sin usar software externo
-
 GuíasHace 5 días
GuíasHace 5 díasOcho funciones de Windows que puedes desactivar para mejorar la seguridad de un PC